Asynchronous Functionality¶
The ploneintranet.asynctasks package aims to facilitate a rich, responsive user experience by offloading long running tasks to a worker instance of Plone.
For example document previews are generated when new documents are uploaded. This happens asynchronously to free up the user’s browser for other tasks. and user notifications arrive in the browser without user interaction.
Similarly, a fast autosave roundtrip is realised by not reindexing the edited page on each edit directly, but deferring the reindexing to an async worker.
Architecture¶
The model we’ve chosen is both simple and powerful: async jobs to be performed, are executed as HTTP requests against a Plone worker.
This provides several benefits:
- Ensures asynchronous jobs can still be performed as if the original user had initiated them.
- Makes it easy to implement an async task, since it is just a normal Plone browser view.
- Makes it easy to debug any issues as the tasks themselves are just HTTP requests.
- Removes the need to give Celery access to the ZODB directly.
- Simplifies deployment, since there is no need for specially-configured async workers - everything runs in Plone instances.
Call flow¶
The following diagram illustrates the call flow:
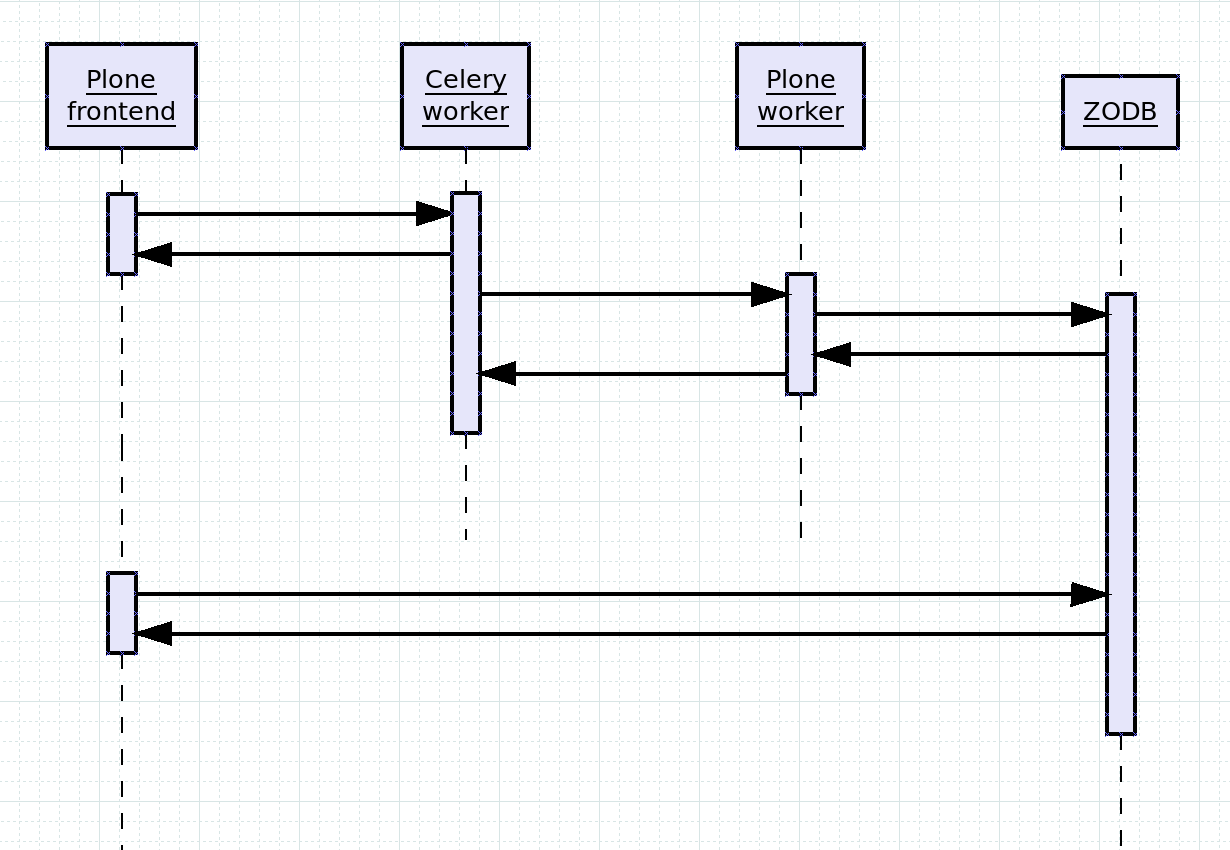
- A Plone frontend serves a view which needs to offload some costly processing.
- The frontend delegates that task to Celery.
- Celery immediately returns, so the initial view can be rendered to the user.
- Celery dispatches the job to a Plone worker.
- The Plone worker commits the result to the ZODB.
- (ZODB returns. Plone worker returns).
At this stage, the original sequence is finished, and the job you would normally perform synchronously has been executed asynchronously and committed to the database, so any following views have access to the results:
- A later view on the Plone frontend accesses the ZODB.
- The ZODB returns a result that includes the async job modifications done above.
Deployment¶
Redis¶
You need a Redis server to store the async messaging queue. For security reasons, we recommend this be installed as a system service so as to be maintained by sysadmin, rather than adding it to buildout where it risks not having security patching performed.
On Ubuntu: sudo apt-get install redis-server.
Celery¶
Async is provided by Celery. Celery is a proven, pure python, distributed task queue.
Celery is included as a dependency in the ploneintranet buildout and is typically run from supervisor. You can run it manually for debugging purposes as follows:
bin/celery -A ploneintranet.asynctasks.celerytasks worker -l debug
(or -l info if you want less verbose logging info)
Plone Workers¶
The diagram above distinguishes between ‘Plone frontend’ and ‘Plone worker’ but that’s not really a requirement. You can run async on a single instance and it will work fine without ZEO: the worker job gets executed by the same instance as soon as the original view is rendered and the instance becomes available.
In a production environment, you would typically use a ZEO setup with multiple Plone instances. Async jobs get executed as HTTP calls on the normal portal URL, which is important since it enables HAProxy to keep track of the load on each instance.
You may want to designate special workers, separate from user-facing frontends, so that any queue buildup of costly processing jobs does not degrade user view performance. You can route async requests to special workers using the X-celery-task-name: your_task_name HTTP header set by ploneintranet.asynctasks using either Nginx rewrites or HAProxy config. You could even maintain separate worker pools for high-priority and low-priority async jobs, distinguished by their task names. YMMV.
If you’re running multiple servers (virtuals) with Plone, each of those needs to have Redis and Celery running.
@@async-status audit view¶
A special helper view {portal_url}/@@async-status implements a self-test on the async functionality.
If the unit tests pass but this one doesn’t, it’s a deployment issue.
Debugging test problems¶
Because part of the async execution is running in a different process, in Celery, you can’t just inject a pdb there. Instead, rely on the extensive logging.
Normally, the test starts up it’s own Celery, but only if there’s not already a Celery process running. To debug test execution, start a Celery instance in debug log level to see what’s going on during the tests:
bin/celery -A ploneintranet.asynctasks.celerytasks worker -l DEBUG
Then run the tests from another terminal.
Adding a new async task¶
If you’re a Plone Intranet developer, it is very easy to add a new async task or to convert an existing piece of functionality into an async job.
Let me walk you through the stack using a working example: performing async object reindexes.
The key thing to understand is, that this is a 3-step process: 1. Prepare the async delegation in Plone. 2. Trigger the delayed http request in Celery. 3. Execute the actual job in Plone.
We’re maintaining Plone task preprocessors (1) in a separate module ploneintranet.asynctasks.tasks to distinguish them from the Celery tasks (2), which are maintained in ploneintranet.asynctasks.celerytasks.
1. Task preprocessor¶
The reason we need to pre-process is, that Celery in step 2 does not have access to anything in Plone, so we need to convert any object references into strings we can pass to Celery.
In ploneintranet.asynctasks.tasks:
from ploneintranet.asynctasks import celerytasks
from ploneintranet.asynctasks.interfaces import IAsyncTask
from ploneintranet.asynctasks.core import AbstractPost
@implementer(IAsyncTask)
class ReindexObject(AbstractPost):
"""Reindex an object asynchronously."""
"""
task = celerytasks.reindex_object
url = '/@@reindex_object'
That’s it. Note that the task and url point forward to the Celery task and worker view we’ll set up in steps 2 and 3 below.
All the heavy lifting here is done in AbstractPost, which:
- Extracts login credentials from the current request
- Sets up a plone.protect authenticator
- Adds a X-celery-task-name http header
- Munges the given relative url into an absolute url on the current context object
Note
Adding a new preprocessor is as simple as subclassing AbstractPost and setting the task and url properties.
2. Celery task¶
The Celery task for our reindex job is very simple:
from ploneintranet.asynctasks.core import dispatch
@app.task
def reindex_object(url, data={}, headers={}, cookies={}):
"""Reindex a content object."""
dispatch(url, data, headers, cookies)
As you can see, this is just a wrapper that turns a dispatch call into a Celery task. app is the Celery API that is set up in ploneintranet.asynctasks.celerytasks.
Note
Adding a new Celery task is as simple as creating a function that calls dispatcher, and decorating that function with @app.task.
3. View that executes the job¶
The actual execution of an async job is handled by a normal Plone view. Since this is the code that will interact with the Plone database, you need to take care to not take any security shortcuts here, which means:
- Register the view with proper view permissions
- Do not disable CSRF protection!
Think about it: we’re cloning an original request and then re-use those credentials to fire off a new request, that will result in a database write. That’s about the definition of a Cross-Site Request Forgery.
ploneintranet.asynctasks plays nice with plone.protect and adds an authenticator to the async request to prove that it’s not an attack.
If you’re developing and debugging the worker view, you’re missing that authenticator (it gets added in the preprocessor step which you’re skipping if you hit the worker view directly.) So you need to add that to help debugging without compromising security.
Here’s the implementation (see ploneintranet.asynctasks.browser.views):
from ploneintranet import api as pi_api
from ploneintranet.asynctasks.tasks import index_to_solr
from Products.Five import BrowserView
from Products.Five.browser.pagetemplatefile import ViewPageTemplateFile
import logging
logger = logging.getLogger(__name__)
class AbstractAsyncView(BrowserView):
"""
Class to be used for browser views executing tasks called by asynctasks.
"""
template = ViewPageTemplateFile("templates/protected.pt")
# Additional parameters to be shown in the form, needs to be set by
# the concrete subclass.
# This must be a list of dict entries with keys `name` and `type`.
# Each entry will cause an input field with that type and name to
# be displayed in the form.
ADDITIONAL_PARAMETERS = []
def authenticated(self):
return self.request.get("_authenticator", False)
class ReindexObjectView(AbstractAsyncView):
"""
Reindex the current object
"""
def __call__(self):
"""
Execute the actual reindex.
The ploneintranet.asynctasks framework provides a plone.protect
authenticator automatically.
For manual testing, render a simple form to provide the
authenticator.
Please do not disable CSRF protection.
"""
if self.authenticated():
if "attributes" in self.request:
attributes = self.request["attributes"]
self.context.reindexObject(idxs=attributes)
else:
self.context.reindexObject()
return self.template()
class ReindexObjectSolrView(AbstractAsyncView):
"""
Reindex the current object to solr only
"""
def __call__(self):
"""
Execute the actual reindex.
The ploneintranet.asynctasks framework provides a plone.protect
authenticator automatically.
For manual testing, render a simple form to provide the
authenticator.
Please do not disable CSRF protection.
"""
if self.authenticated():
logger.info("Indexing context to solr")
index_to_solr(self.context)
return self.template()
class GeneratePDFView(AbstractAsyncView):
"""
Generate a PDF for the current object
"""
def __call__(self):
"""
Execute the pdf generation.
The ploneintranet.asynctasks framework provides a plone.protect
authenticator automatically.
For manual testing, render a simple form to provide the
authenticator.
Please do not disable CSRF protection.
"""
if self.authenticated():
logger.info("Generating previews for %s", self.context.absolute_url(1))
if self.request.get("purge"):
pi_api.previews.purge_previews(self.context)
pi_api.previews.generate_pdf(self.context)
return self.template()
The corresponding view template is as follows:
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"
xmlns:tal="http://xml.zope.org/namespaces/tal"
xmlns:metal="http://xml.zope.org/namespaces/metal"
xmlns:i18n="http://xml.zope.org/namespaces/i18n"
lang="en"
i18n:domain="ploneintranet">
<body>
<h1>Protected async handler</h1>
<div tal:condition="not:view/authenticated">
<p>Manual execution of async tasks requires confirmation
in order to exclude CSRF attacks.</p>
<form>
<span tal:replace="structure context/@@authenticator/authenticator"/>
<tal:additional repeat="entry view/ADDITIONAL_PARAMETERS">
<label>${entry/name}
<input name="${entry/name}" type="${entry/type}" />
</label><br />
</tal:additional>
<input type="submit" value="confirm action"/>
</form>
</div>
<div tal:condition="view/authenticated">
<p>Action confirmed and executed.</p>
</div>
</body>
</html>
Finally, the view is registered for cmf.ModifyPortalContent since only users with write access should be allowed to trigger a reindex.
<browser:page
name="reindex_object"
for="*"
class=".views.ReindexObjectView"
permission="cmf.ModifyPortalContent"
layer="..interfaces.IPloneintranetAsyncLayer"
/>
Note
The actual business logic for executing an async task can be developed as a normal Plone view which you can access directly.
Calling the task¶
Now the async job pipeline is setup, all you have to do is to import the task preprocessor in your own view code somewhere, and calling it:
from ploneintranet.asynctasks import tasks
tasks.ReindexObject(self.context, self.request)()
Note
Triggering an async job is as simple as instantiating and then calling the preprocessor task you prepared above in step 1.
Note the final parentheses, wich is a __call__ that takes various extra arguments with which you can tune both the requests.post and the celery.apply_async calls that are taking place under the hood.
A fictitious call to a view that expects form arguments, which is called with a delay of two seconds, could for example look like:
tasks.GoNuts(self.context, self.request)(data={'nut':'hazel'}, countdown=2)
See the IAsyncTask interface for the full API:
-
interface
ploneintranet.asynctasks.interfaces.IAsyncTask(context, request)¶ Execute a request asynchronously via Celery.
Extracts authentication credentials from a original request and submits a new post request, taking special care that all calls are properly serialized.
-
task= <zope.interface.interface.Attribute object>¶ A Celery @app.task callable
-
url= <zope.interface.interface.Attribute object>¶ A url to be called, relative to self.context.absolute_url()
-
data= <zope.interface.interface.Attribute object>¶ A dictionary with request cookie key: value pairs
-
headers= <zope.interface.interface.Attribute object>¶ A dictionary with request header key: value pairs
A dictionary with request cookie key: value pairs
-
__init__()¶
-
__call__(...) <==> x(...)¶
-
Re-using ploneintranet.asynctasks outside of ploneintranet¶
Celery is typically set up as follows:
- a celeryconfig module contains the configuration
- a celerytasks module loads that configuration module and creates an app
- a Celery worker is then run against the celerytasks module.
Because of the way Celery wraps tasks in decorators and is quite picky about names and module paths, this means that you cannot import anything from the ploneintranet.celerytasks module.
However, we factored the heavy lifting infrastructure out into a separate ploneintranet.asynctasks.core module which you can easily use to build your own Celery tasks:
- ploneintranet.asynctasks.core.AbstractPost is a generic engine for creating task preprocessors. See above how little work is required to subclass it into a custom preprocessor.
- ploneintranet.asynctasks.core.dispatch is a generic engine for executing http requests from Celery.
Note
By importing ploneintranet.asynctasks.core you can easily create your own tasks preprocessors and celerytasks.
-
class
ploneintranet.asynctasks.core.AbstractPost(context, request=None)¶ Execute a HTTP POST request asynchronously via Celery.
Extracts authentication credentials from a original request and submits a new post request, taking special care that all calls are properly serialized.
Sets a X-celery-task-name http header for task request routing in HAProxy etc. YMMV.
This task is suitable as a base class for more specialized subclasses. It is structured as if it were an adapter but it is not registered or used as an adapter.
See tasks.Post for an actual implementation example.
-
__init__(context, request=None)¶ Extract credentials.
-
transform_url(url)¶ Compute the URL for this task
If a mapping is provided replace the portal URL with another one (usefull to bypass the publication stack)
-
__call__(url=None, data={}, headers={}, cookies={}, **kwargs)¶ Start a Celery task that will execute a post request.
The optional url argument may be used to override self.url. The optional data, headers and cookies args will update the corresponding self.* attributes.
self.task.apply_async will be called and is expected to call url with self.headers as request headers, self.cookie as request cookies, and self.data as post data via the python request library.
**kwargs will be passed through as arguments to celery apply_async so you can set async execution options like countdown, expires or eta.
Returns a <class ‘celery.result.AsyncResult’> when running async, or a <class ‘celery.result.EagerResult’> when running in sync mode.
-
-
ploneintranet.asynctasks.core.dispatch(url, data={}, headers={}, cookies={})¶ Execute a HTTP POST via the requests library. This is not a task but a building block for Celery tasks.
Parameters: - url (str) – URL to be called by celery, resolvable behind the webserver (i.e. {portal_url}/path/to/object)
- data (dict) – POST variables to pass through to the url
- headers (dict) – request headers.
- cookies (dict) – request cookies. Normally contains __ac for Plone.
This code path is executed in Celery, not in Plone! You cannot insert a pdb. Instead, debug via log messages. To see the log messages, run celery manually:
bin/celery -A ploneintranet.asynctasks.celerytasks worker -l debug
Websockets push¶
The following is not implemented yet but sketches our full vision for the async subsystem.
Todo
The following details how the final, full async system should work, making use of websockets.
Final goal¶
In the example of document preview generation, a full roundtrip would be as follows:
- Jane logs into the Intranet.
- Her browser attempts to open a websocket connection to a Tornado Websocket server.
- The Tornado server authenticates the socket open request against Plone using Jane’s __ac cookie.
- Jane uploads a document to a workspace.
- Plone Intranet handles the object created event, and adds a document preview generation task to the async queue.
- Celery makes an HTTP request to the Plone Worker instance, authenticated as Jane.
- Plone Worker instance converts document/generates preview.
- Plone Worker instance sends a “done” message to a special frontend queue.
- Tornado server publishes “done” message to Jane’s browser together with URL to fetch HTML snippet from.
- Browser receives a pat-push marked up message from the websocket.
- Browser executes the pat-push injection: loads the additional HTML snippet and replaces the placeholder preview image with the actually generated preview image.
Technology stack¶
- Tornado will provide a simple websocket server that authenticates against Plone
- Redis provides message queues
- Celery provides a simple worker to consume tasks from Redis and perform HTTP requests to Plone Worker instances
As we are using Celery, the message queue can be swapped out per deployment.
pat-push¶
See https://github.com/ploneintranet/ploneintranet.prototype/issues/75
Previews that have been generated asynchronously get pushed back into the DOM without requiring a refresh of the user’s browser.
To do this we generate a HTML snippet of the preview which contains the source and target attributes for pat-inject. This snippet is sent to the browser over a websocket (described above). pat-inject-async attaches an event handler to on_message event of SockJS
Todo
Pat-push is not implemented yet